Platz sparen
Wann immer analoge oder digitale Bildsignale aufgezeichnet werden, entstehen enorme Datenmengen. Ein unkomprimiertes HD-, 4K- oder gar 8K-Signal würde bereits nach kurzer Zeit riesige Speicherkapazitäten beanspruchen. Bereits in der Frühzeit der Digitalisierung waren die Datenraten für die damaligen Speicher- und Übertragungssysteme kaum beherrschbar. Die einzige praktikable Lösung bestand darin, die Datenmenge gezielt zu reduzieren.
Dieses Prinzip gilt bis heute. Ob Streaming-Plattformen, Fernsehsender, Smartphones oder digitale Kinoprojektion – nahezu alle nutzen Kompressionsverfahren, um Filme effizient speichern, übertragen und wiedergeben zu können.
Normierung
Hierfür werden standardisierte Videokodierungsverfahren eingesetzt. Zu den bekanntesten gehört die MPEG-Familie. MPEG-2 wurde beispielsweise für DVD und digitales Fernsehen eingesetzt, während MPEG-4 die Grundlage vieler moderner Formate bildet. Später kamen Verfahren wie H.264/AVC, H.265/HEVC, AV1 oder VVC hinzu, die bei gleicher Qualität deutlich geringere Datenraten ermöglichen.
Die Standards werden von internationalen Gremien entwickelt und kontinuierlich weiterentwickelt. Neben der Bildkompression regeln sie häufig auch Audiokompression, Synchronisation und das Zusammenführen verschiedener Datenströme (Multiplexing).
Arbeitsweise
Daten zu reduzieren, ohne die Bildqualität übermäßig zu beeinträchtigen, ist ein komplexes Unterfangen. Dabei werden gezielt Eigenschaften der menschlichen Wahrnehmung genutzt. Informationen, die das Auge nur schwer erkennen kann, werden stärker komprimiert als besonders auffällige Bildbestandteile.
Da der Mensch Helligkeitsunterschiede wesentlich präziser wahrnimmt als Farbunterschiede, werden Helligkeits- und Farbinformationen unterschiedlich behandelt. Dies erklärt auch die weit verbreiteten Farbabtastungen wie 4:2:2 oder 4:2:0.
Intraframe-Kompression
Im Folgenden werden wichtige Verfahren beschrieben, die sich auf einzelne Bilder beziehen. Solche Methoden kommen beispielsweise auch bei Standbildern im JPEG-Verfahren zum Einsatz. Moderne Codecs kombinieren dabei verschiedene Techniken, um eine möglichst hohe Effizienz zu erzielen.
Während man bei JPEG die Stärke der Kompression oft direkt beeinflussen kann, arbeiten Videocodecs mit komplexen Regelmechanismen, die Datenrate, Qualität und Bildinhalt automatisch gegeneinander abwägen.
Datenreduktion – Run Length Coding (RLC)
Eine der einfachsten Formen der Datenreduktion besteht darin, sich wiederholende Informationen zusammenzufassen. Statt denselben Pixelwert mehrfach zu speichern, wird nur der Wert selbst und die Anzahl seiner Wiederholungen festgehalten. Dieses Verfahren nennt man Run Length Coding (RLC).
Bei großen gleichfarbigen Flächen – etwa einem Himmel oder einer Wand – lässt sich dadurch Speicherplatz einsparen, ohne die Bildqualität sichtbar zu verändern.
Discrete Cosine Transformation (DCT)
Die DCT gehört zu den wichtigsten Grundlagen moderner Bild- und Videokompression. Dabei wird das Bild in kleine Blöcke zerlegt, traditionell oft 8 × 8 Pixel groß. Diese Bildinformationen werden anschließend mathematisch in Frequenzanteile umgerechnet.
Große gleichmäßige Flächen erzeugen niedrige Frequenzen, feine Details hohe Frequenzen. Dadurch lassen sich Bildinformationen deutlich effizienter beschreiben und später komprimieren. Der sogenannte DC-Koeffizient beschreibt den durchschnittlichen Helligkeits- oder Farbwert eines Blocks. Die übrigen AC-Koeffizienten enthalten die Abweichungen von diesem Durchschnitt.
Quantisierung
Während die DCT selbst noch weitgehend verlustarm arbeitet, entstehen bei der Quantisierung die eigentlichen Qualitätsverluste. Dabei werden die errechneten Frequenzwerte vereinfacht oder gerundet.
Besonders hohe Frequenzen – also feine Details – werden stärker reduziert, da das menschliche Auge deren Verlust weniger deutlich wahrnimmt. Genau hier entstehen jedoch auch typische Kompressionsartefakte wie Blockbildung, Banding oder Kantenfehler. Die Quantisierung bestimmt maßgeblich das Verhältnis zwischen Datenrate und Bildqualität. Je stärker sie eingreift, desto kleiner werden die Dateien – allerdings auf Kosten der Bildtreue.
Kodierung
Nach DCT und Quantisierung folgt die eigentliche Kodierung. Dabei werden die verbleibenden Werte möglichst effizient gespeichert. Da benachbarte Bildbereiche häufig ähnliche Werte besitzen, genügt es oft, nur die Unterschiede zum Ausgangswert festzuhalten.
Zusätzliche Verfahren sorgen dafür, dass häufig auftretende Werte mit besonders kurzen Codes gespeichert werden. Dadurch lässt sich die Datenmenge weiter reduzieren.
Huffman-Algorithmus
Eine klassische Methode hierfür ist die Huffman-Kodierung. Sie vergibt kurze Binärcodes für häufig vorkommende Werte und längere Codes für seltene Werte. Auf diese Weise können die Daten besonders platzsparend gespeichert werden. Encoder und Decoder müssen dabei dieselben Tabellen verwenden, damit die komprimierten Informationen später wieder korrekt rekonstruiert werden können.
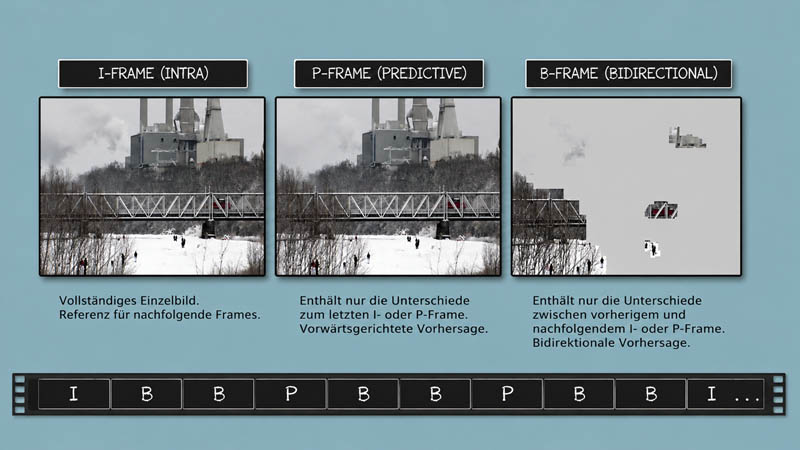
Bis hierher wurden Verfahren beschrieben, die innerhalb einzelner Bilder arbeiten. Moderne Videocodecs nutzen zusätzlich zeitliche Zusammenhänge zwischen aufeinanderfolgenden Bildern und können dadurch noch deutlich höhere Kompressionsraten erreichen.
Diese Verfahren werden im zweiten Teil anhand der Interframe-Kompression und der Bildanalyse zwischen mehreren Bildern erläutert.